1. General
1.1 HORTONWORKS DATAFLOW (HDF™)
HDF makes streaming analytics faster and easier, by enabling accelerated data collection, curation, analysis and delivery in real-time, on-premises or in the cloud through an integrated solution with Apache NiFi, Kafka and Storm.
1.2 What is Apache NiFi
A real-time integrated data logistics and simple event processing platform
Apache NiFi automates the movement of data between disparate data sources and systems, making data ingestion fast, easy and secure.
1.3 What is Elasticsearch
A Open Source, Distributed, RESTful Search Engine which same as Apache Solr.
1.4 Background
This project named HDF-experimentations, the goal is to understand how Apache NiFi works and how we can use it in production with large data. Get data from PostgreSQL and put them into Elasticsearch. We want to compare the performance of Apache Nifi with the performance of Apache Camel.
The official site of Apache Nifi has 2 releases version: 1.0.0 and 0.7.1, Hortonworks has a version named HDF 2.0 include Apache NiFi 1.0.0 and it is OpenSource., so we will use HDF 2.0 by default.

2. Environnement
- Ubuntu 16.04 (X64)
- java version "1.8.0_111"
- HDF 2.1.1 (nifi-1.1.0.2.1.1.0-2), HDF released a new version on 19/12/2016.
- Elasticsearch 2.4.1 (Kopf plugin)
- Kibana 4.6.2 (Sense plugin)
2.1 Installation HDF 2.0 (Standalone)
wget http://public-repo-1.hortonworks.com/HDF/2.0.0.0/HDF-2.0.0.0-579.tar.gz
tar -xvf HDF-2.0.0.0-579.tar.gz
cp -r HDF-2.0.0.0-579 your/path
# add path
echo "PATH=`your/path`/HDF-2.0.0.0-579/nifi/bin:$PATH" > ~/.bashrc
# reload path
source ~/.bashrc
Using this command nifi.sh start to execute program, we could access webUI via browser http://localhost:8080/nifi
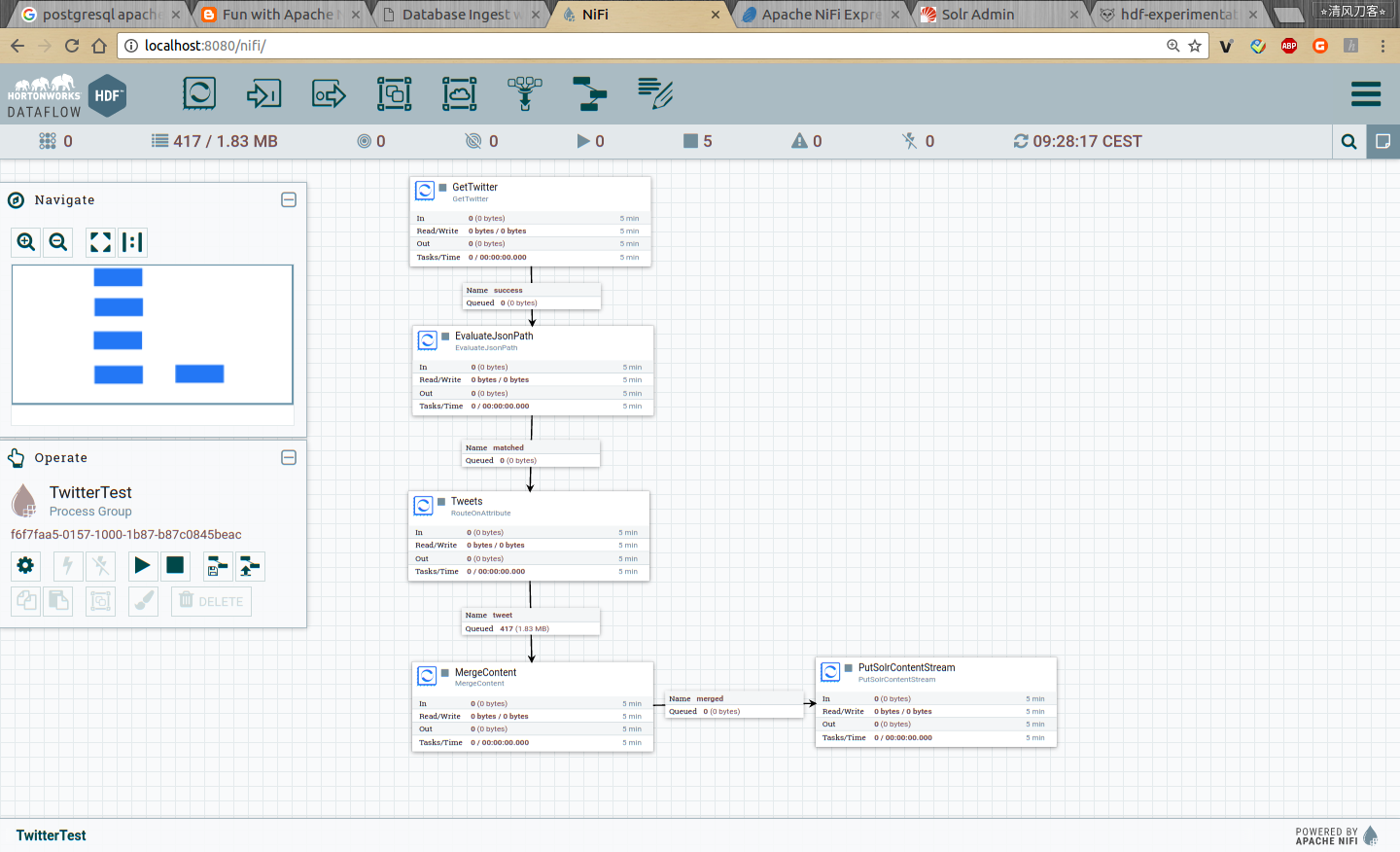
2.2 Installation ElasticSearch
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/zip/elasticsearch/2.4.1/elasticsearch-2.4.1.zip
unzip elasticsearch-2.4.1.zip
cp -r elasticsearch-2.4.1 your/path
# add path
echo "PATH=`your/path`/elasticsearch-2.4.1/bin:$PATH" > ~/.bashrc
# reload path
source ~/.bashrc
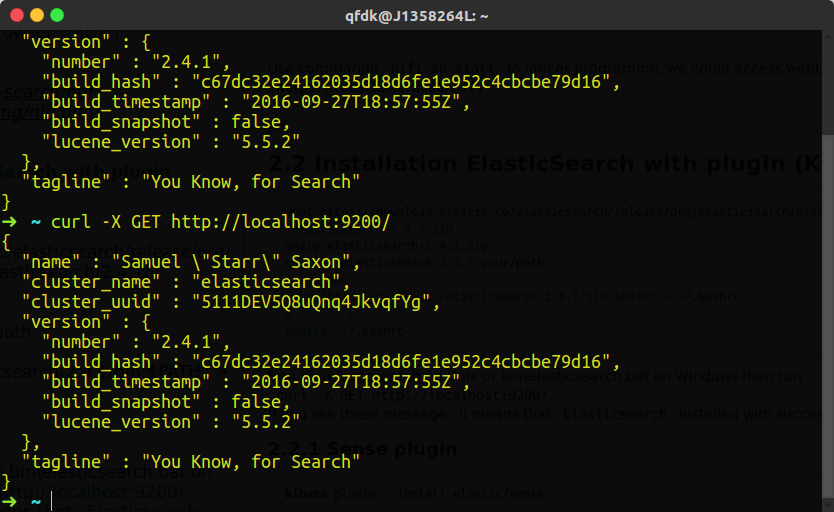
Run bin/elasticsearch on Unix or bin\elasticsearch.bat on Windows then run curl -X GET http://localhost:9200/
If you see these messages, it means that Elasticsearch installed with success.
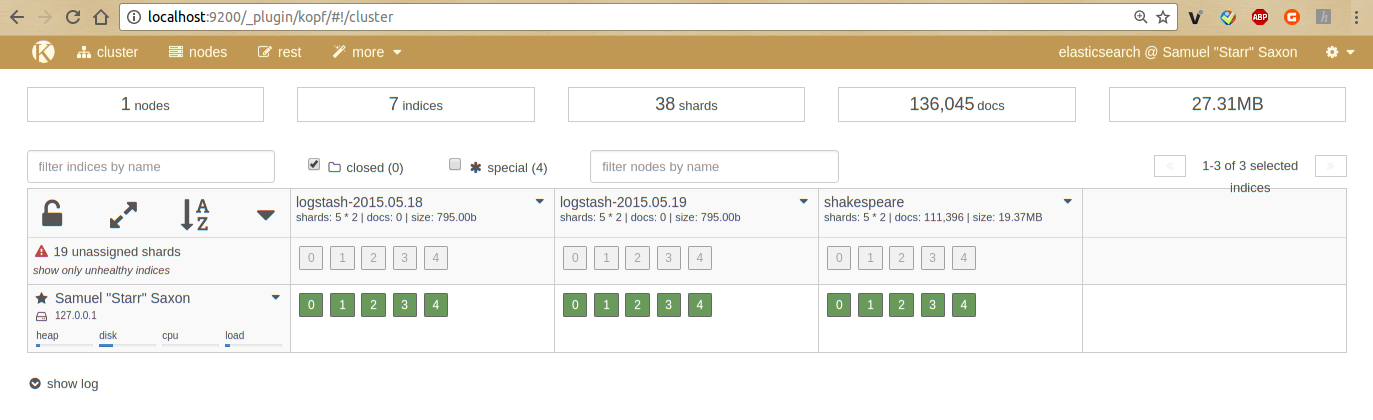
2.2.1 Kopf plugin for ElasticSearch
Kopf is a simple web administration tool for elasticsearch written in JavaScript + AngularJS + jQuery + Twitter bootstrap.
Run this command,
plugin install lmenezes/elasticsearch-kopf/2.0
Point your browser at http://localhost:9200/_plugin/kopf/
2.3 Installation Kibana
wget https://download.elastic.co/kibana/kibana/kibana-4.6.2-linux-x86_64.tar.gz
tar -xvf kibana-4.6.2-linux-x86_64.tar.gz
cp -r kibana-4.6.2-linux-x86_64 your/path
# add path
echo "PATH=`your/path`/kibana-4.6.2-linux-x86_64/bin:$PATH" > ~/.bashrc
# reload path
source ~/.bashrc
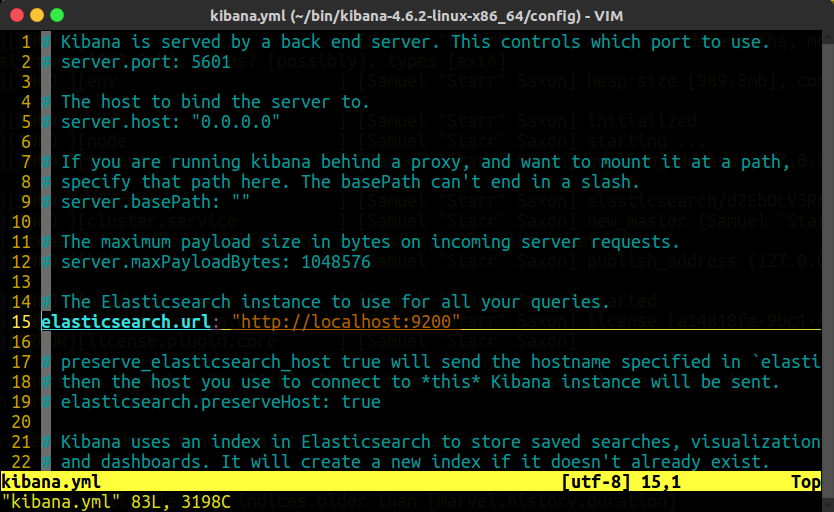
Open config/kibana.yml in an editor, set the elasticsearch.url to point at your Elasticsearch instance.
Point your browser at http://localhost:5601 , you could see the web ui.
2.3.1 Sense plugin for Kibana
Sense is a handy console for interacting with the REST API of Elasticsearch.
kibana plugin --install elastic/sense
2.4 Put the data in ElasticSearch/Apache Solr using Twitter API
- MyElasticSolr.xml
- MyTwitterTemplate.xml
2.4.1 Geo Map(Kibana)
We could format the Input JSON, using JoltTransformJSON. More informations about JOLT. There is a demo available at jolt-demo.appspot.com. You can paste in JSON input data and a Spec, and it will post the data to server and run the transform.
- latitude: -90 ~ 90
- longitude: -180 ~ 180
Warning: In elasticSearch an array representation with [lon,lat], NOT [lat,lon].
Everybody gets caught at least once: string geo-points are "latitude,longitude" , while array geo-points are [longitude,latitude]—the opposite order!
Originally, both strings and arrays in Elasticsearch used latitude followed by longitude. However, it was decided early on to switch the order for arrays in order to conform with GeoJSON.
The result is a bear trap that captures all unsuspecting users on their journey to full geolocation nirvana.
Mapping is very important for a search engine like Elasticsearch or Apache Solr.
These codes could be used in Sense.
GET twitter/_search
{
"query": {
"match_all": {}
}
}
DELETE twitter
PUT twitter
GET /twitter/_search/template
GET _template
DELETE _template/twitter
PUT _template/twitter
{
"template": "twitter",
"order": 1,
"settings": {
"number_of_shards": 1
},
"mappings": {
"tweet": {
"_all": {
"enabled": true
},
"dynamic_templates": [
{
"message_field": {
"match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"index": "analyzed",
"omit_norms": true
}
}
},
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"index": "analyzed",
"omit_norms": true,
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"ignore_above": 256
}
}
}
}
}
],
"properties": {
"text": {
"type": "string"
},
"place": {
"properties": {
"country": {
"index": "not_analyzed",
"type": "string"
},
"name": {
"index": "not_analyzed",
"type": "string"
}
}
},
"coordinates": {
"properties": {
"coordinates": {
"type": "geo_point"
},
"type": {
"type": "string"
}
}
}
}
}
}
}
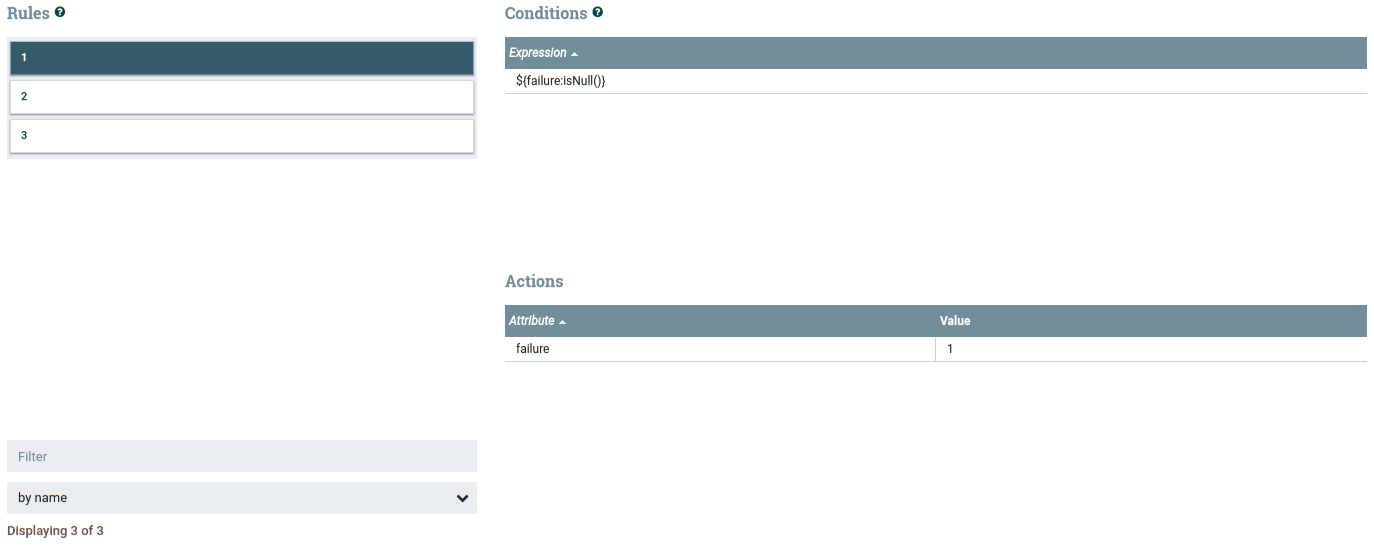
2.4.2 Retry/Failure ?
In a NiFi data-flow, it’s a common best practice to draw failure relationships so that they loop back to the feeding processor rather than terminating them. This way, you don’t lose data when it fails to process and when it does fail, you can see that it has gone down the failure relationship and can troubleshoot the issue. However, this can also result in an infinite loop...
We could use a UpdateAttribute processor with three rules configured (3 times for retry failed). The rules were added using the Advanced tab in the processor but you must use Apache NiFi Expression Language.
2.4.3 Other solution from Internet
This is definitely something you can do. So let's use your example.
You have a PutFile processor and if a given object routes to failure
three times you want to be able to detect that and do something else.
Here is how:
Before PutFile use an UpdateAttribute processor configured with a
single property 'times-through-here' and a value of '0'After PutFile's failure relationship route the results to another
UpdateAttribute processor. In it set an attribute property
'times-through-here' with a value of '${times-through-here:plus(1)}'After that UpdateAttribute route the data to a RouteOnAttribute.
The route on attribute should have a property of 'too many' with a
value of '${times-through-here:ge( 3 )}'. For the 'too many'
relationship this is your stuff that has failed too many times route
it wherever you like or auto terminate. For the 'no match'
relationship you can route it back to the PutFileUsing this same pattern and expression language capability you can
imagine a variety of powerful things you can do to control it.
If you have any questions let us know. We could turn this into a good
FAQ type entry complete with screenshots and templates.
We need to get our expression language docs on the website. In the
mean time you can view them in the running app through the help
screen.
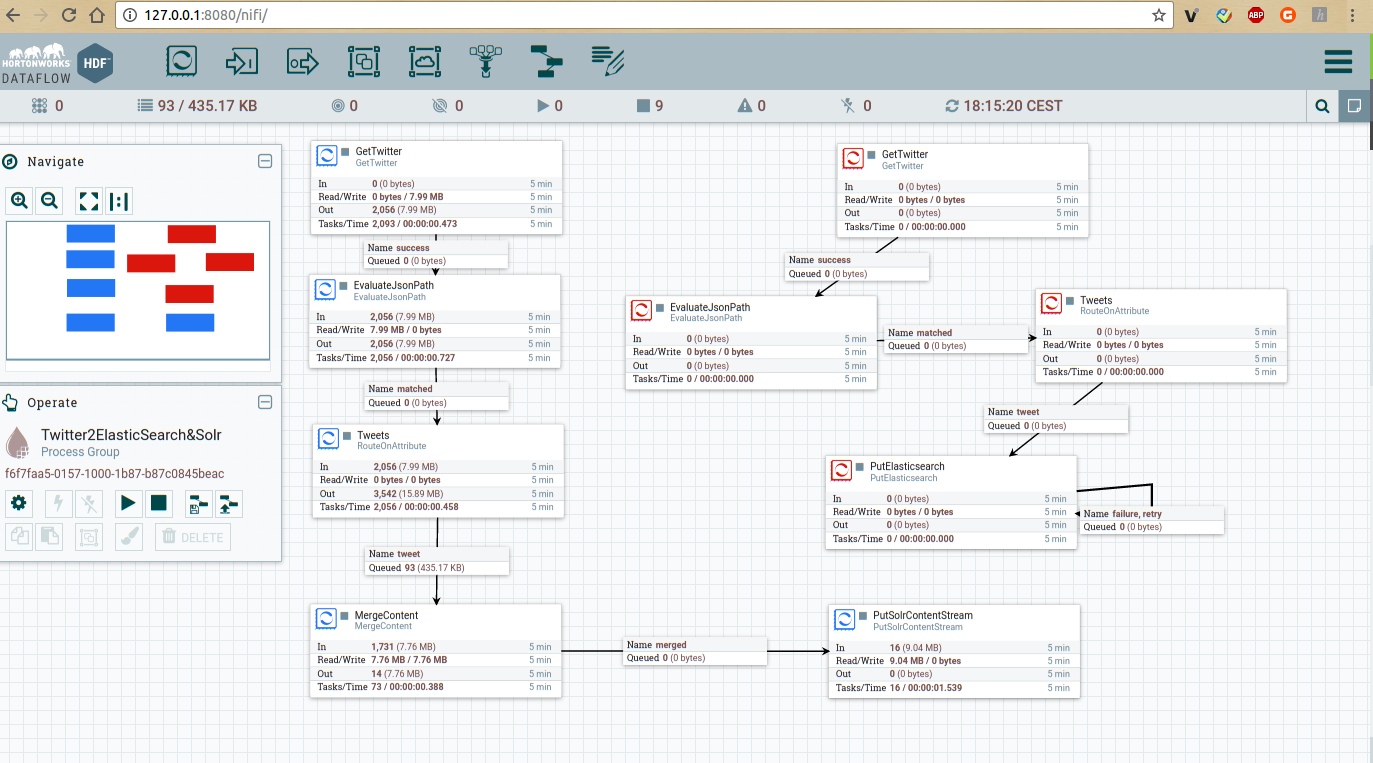
Examples for Aapche NiFi/Zeppelin
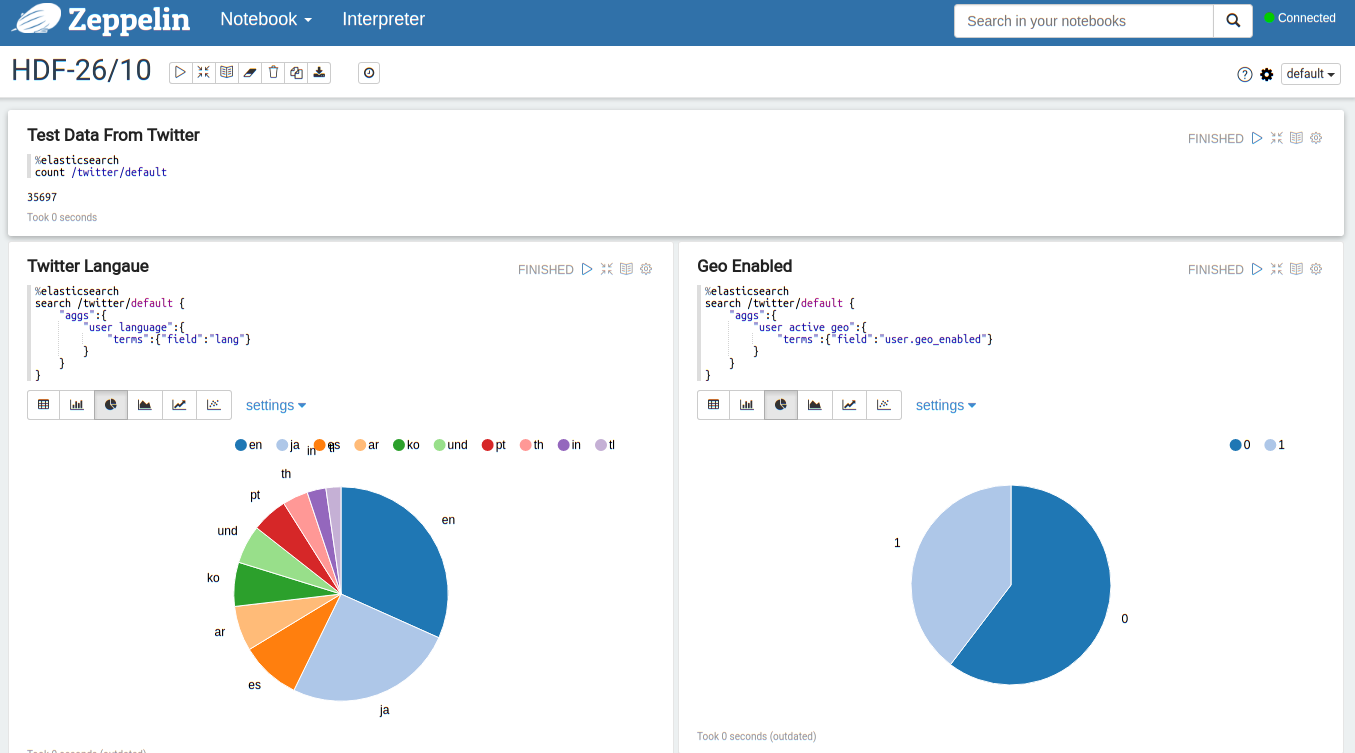
Examples for Kibana
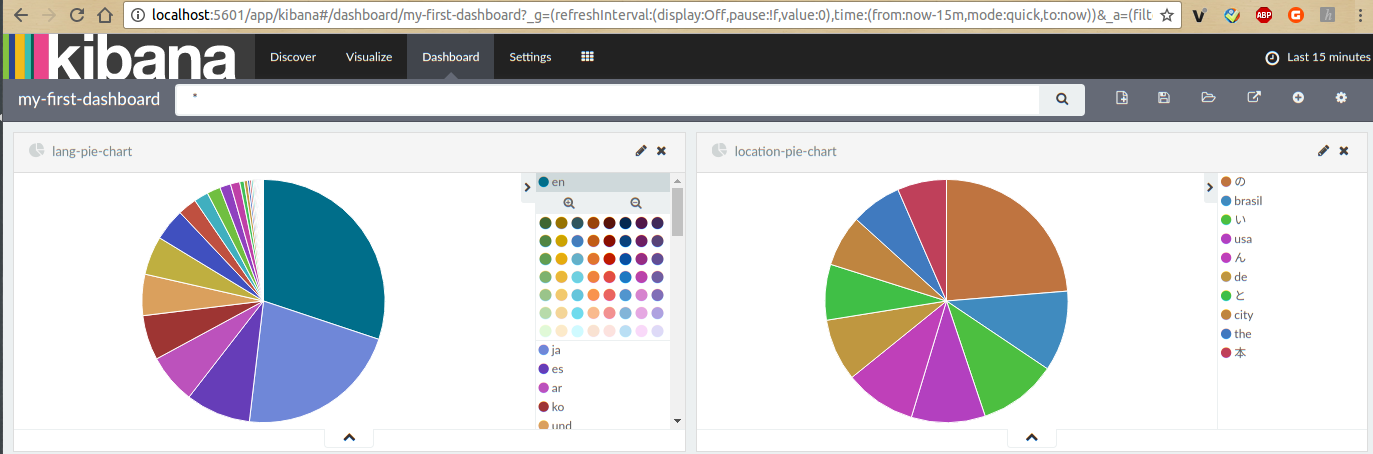
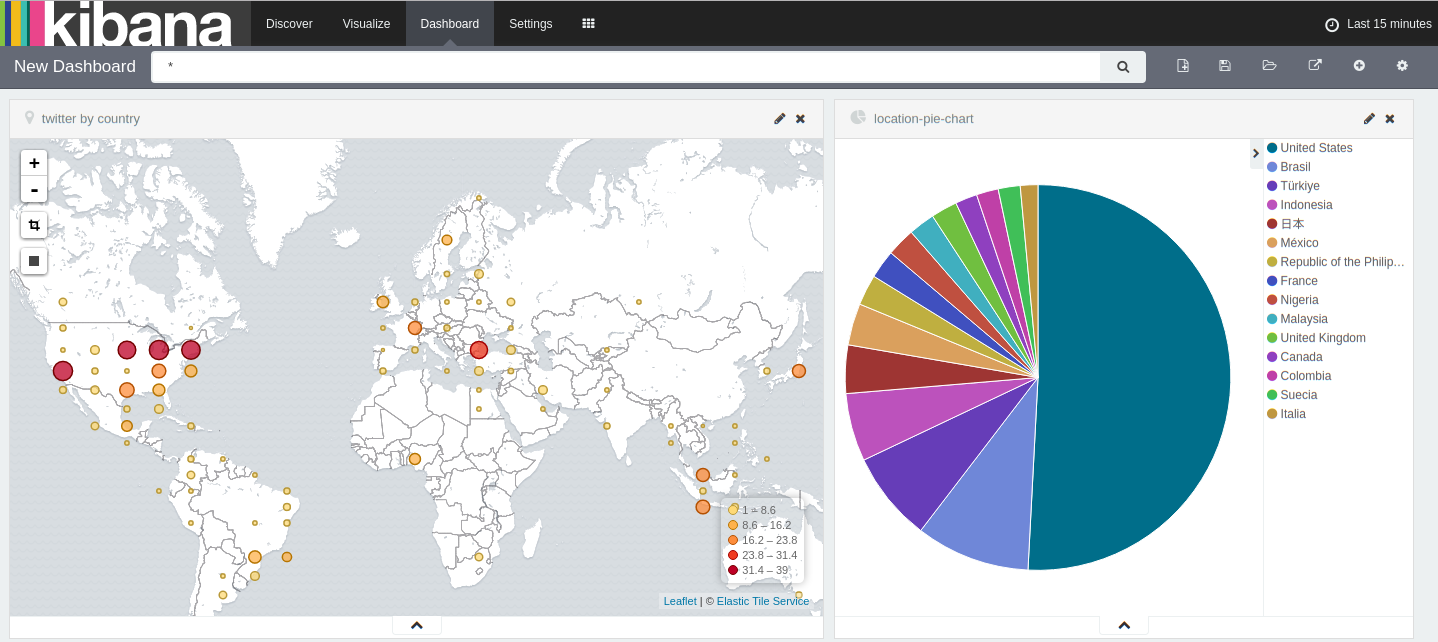
2.5 Build custom processor and debug
2.5.1 Custom processor with maven and eclipse
- Command to create an Apache Nifi project
mvn archetype:generate -DarchetypeGroupId=org.apache.nifi -DarchetypeArtifactId=nifi-processor-bundle-archetype -DarchetypeVersion=0.2.1 -DnifiVersion=0.2.1
- Sample inputs to generate a maven project
Define value for property 'groupId': : com.hortonworks
Define value for property 'artifactId': : debug-processor
Define value for property 'version': 1.0-SNAPSHOT: :
Define value for property 'artifactBaseName': : debug
Define value for property 'package': com.hortonworks.processors.debug: :- This will create an archetype maven project for a custom processor with the package name, artifactId, etc specified above.
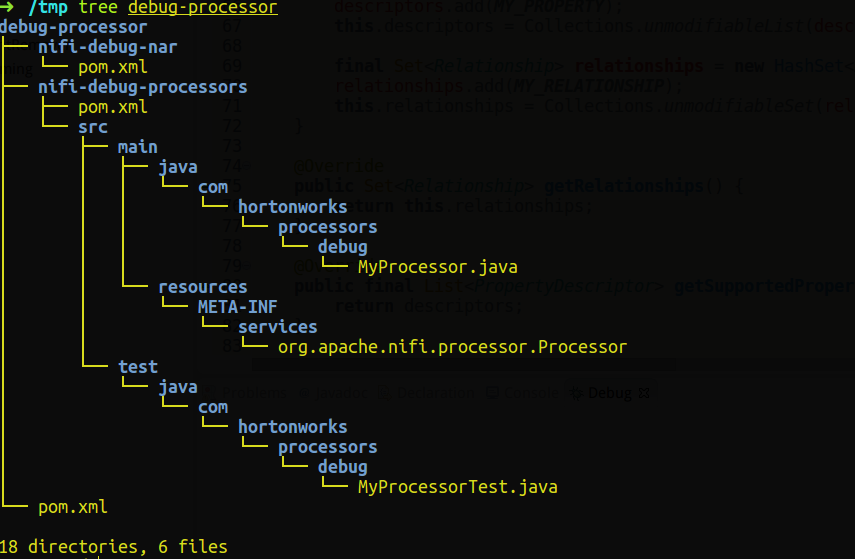
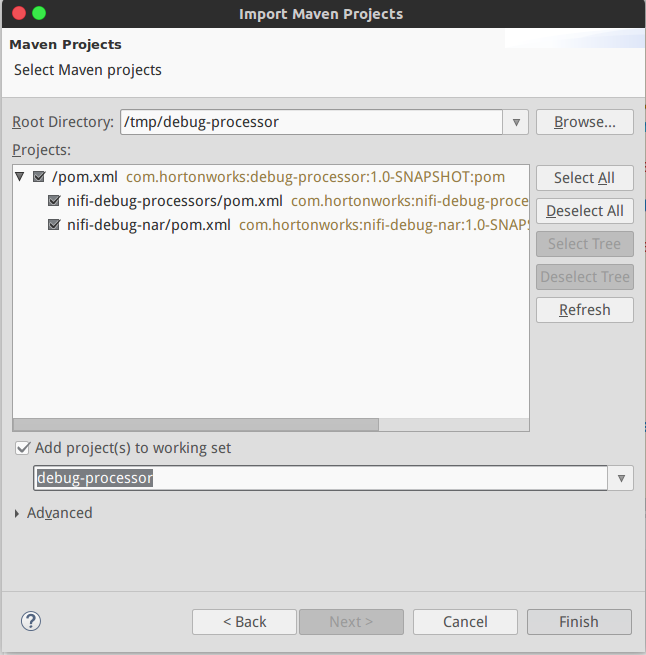
- Import to Eclipse
File > Import > Maven > Existing Maven projects, named it debug-processor
- You should see that archi in your eclipse
- To run maven compile
- In Eclipse, under
Package Explorerselect debug-processor and then click Run configuration on the tools bar
- In Eclipse, under
- Then double click 'Maven Build'. It will prompt you for the configuration. Enter the below
- Name: nifi-debug
- Base dir: /home/qfdk/workspace/debug-processors
- Under 'Goals': clean package
- Under Maven Runtime: (scroll down to see this option).
- Configure > Add > click ‘Directory’ and navigate to mvn install: /usr/share/apache-maven > OK > Finish > Select apache-maven > Apply > OK
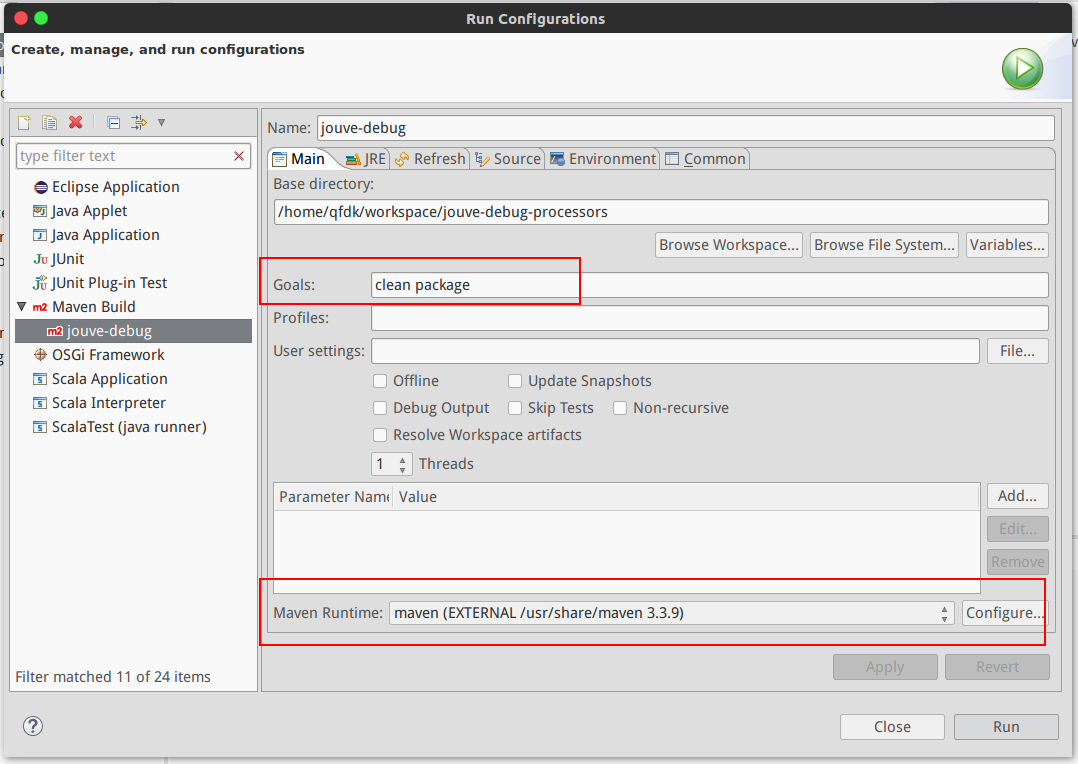
- To compile with maven
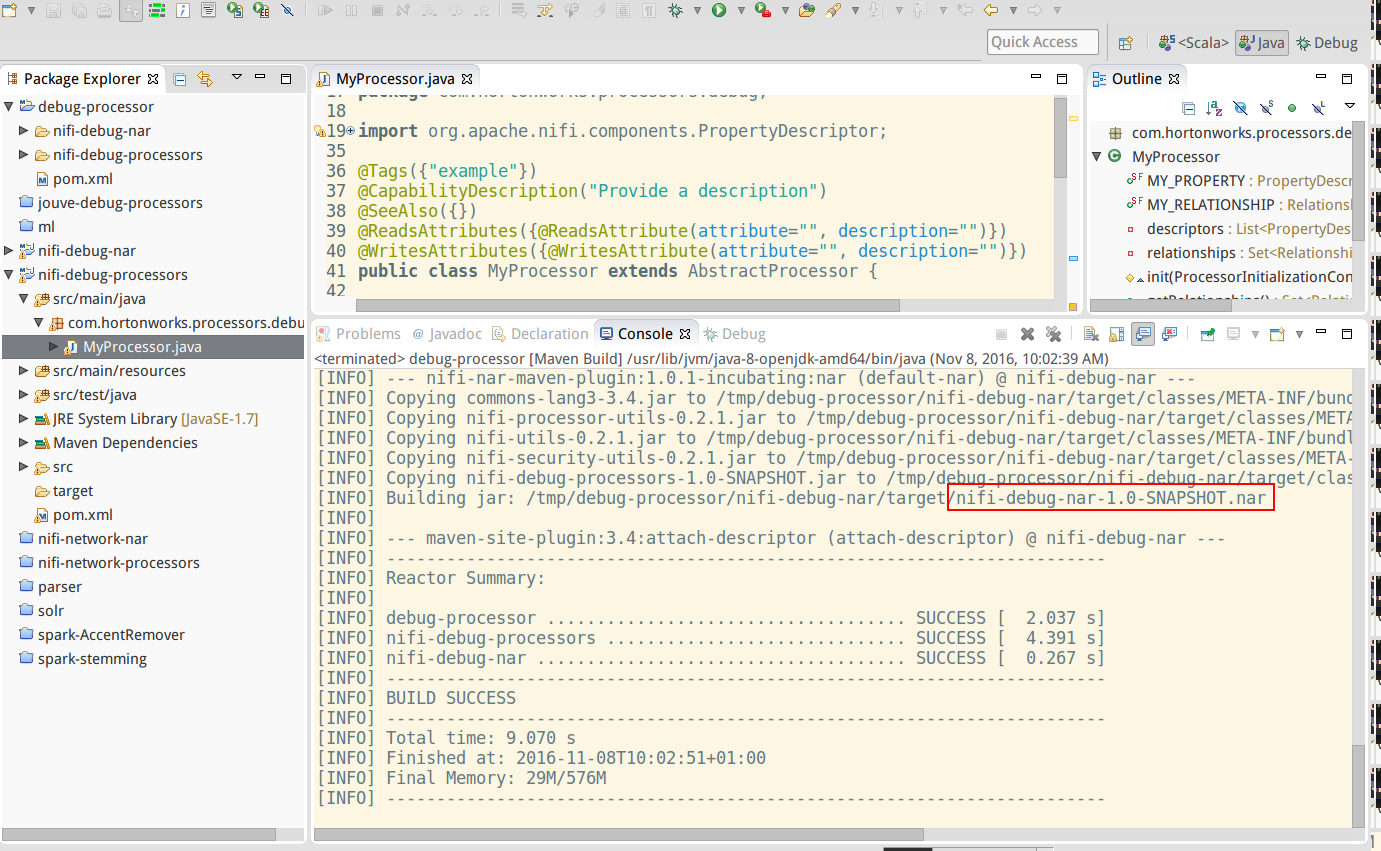
- To run Junit to confirm processor is working correctly
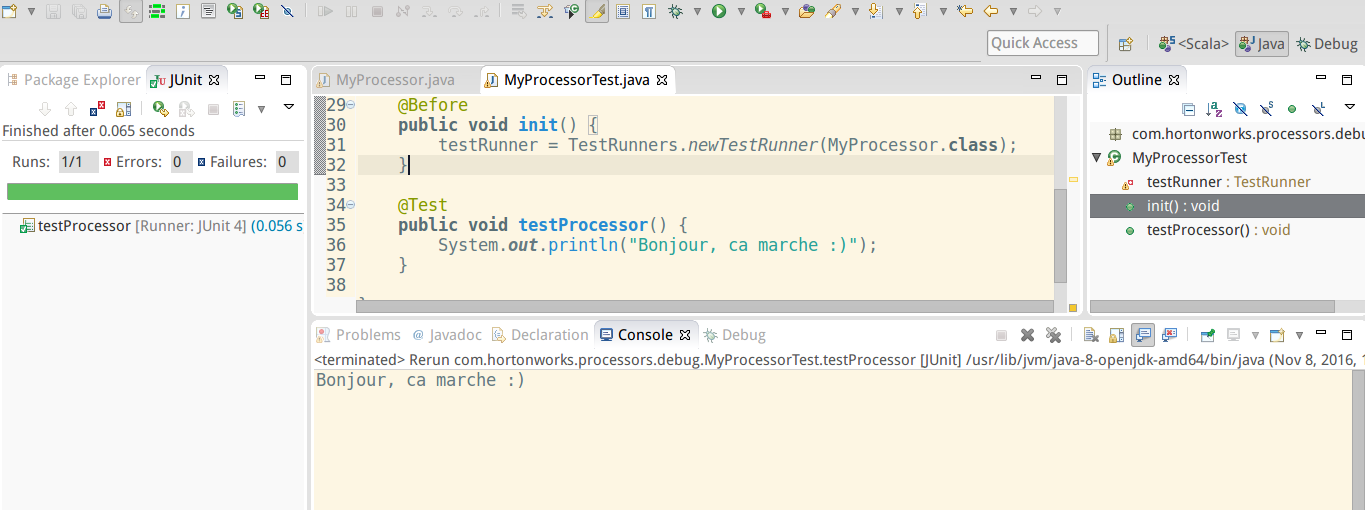
- In Eclipse, under Package Explorer select nifi-debug-processors and then click:
- Run > Run as > JUnit test
- In Eclipse, under Package Explorer select nifi-debug-processors and then click:
- you should see below (success)
- Then you copy
nifi-debug-nar-1.0-SNAPSHOT.narin the lib of Apache Nifi, restart your nifi server, you should see your processor in the list.
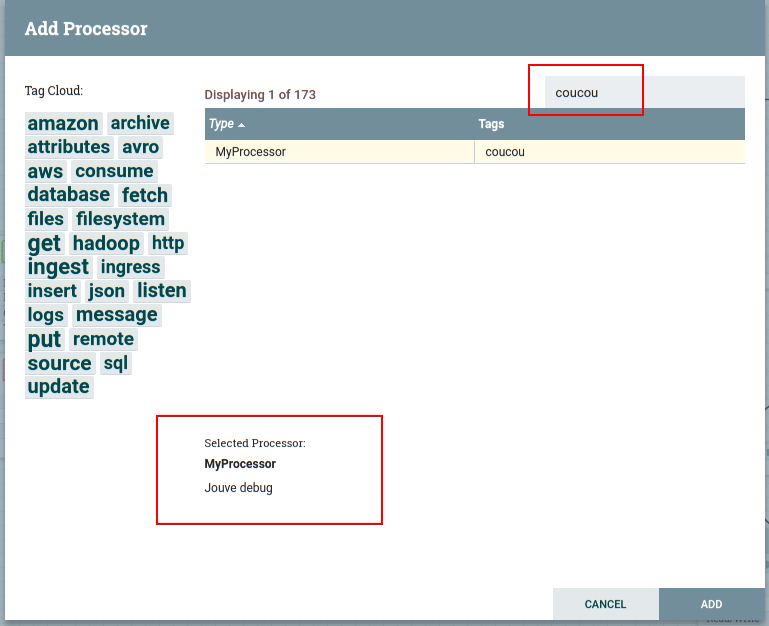
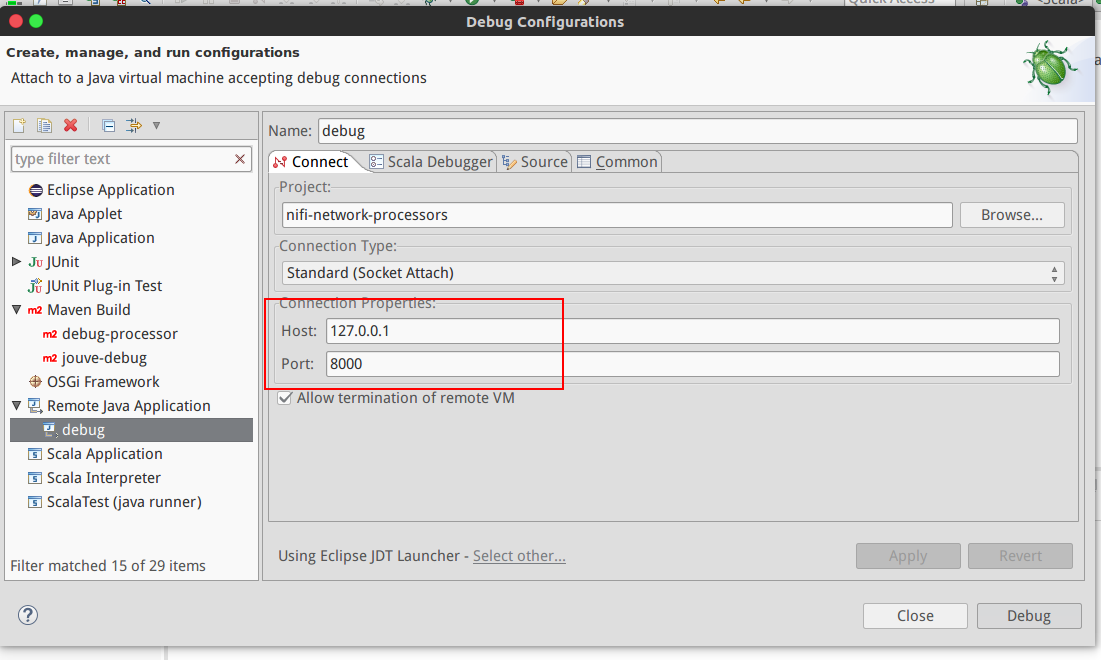
2.5.2 Debug (Remote mode)
In NiF's conf directory in bootstrap.conf there is a line commented out like this:
#java.arg.debug=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000
Uncomment that line and restart NiFi, the Java process will be listening for a debug connection on port 8000. If you want the process to wait for a connection before starting, you can also set suspend=y.
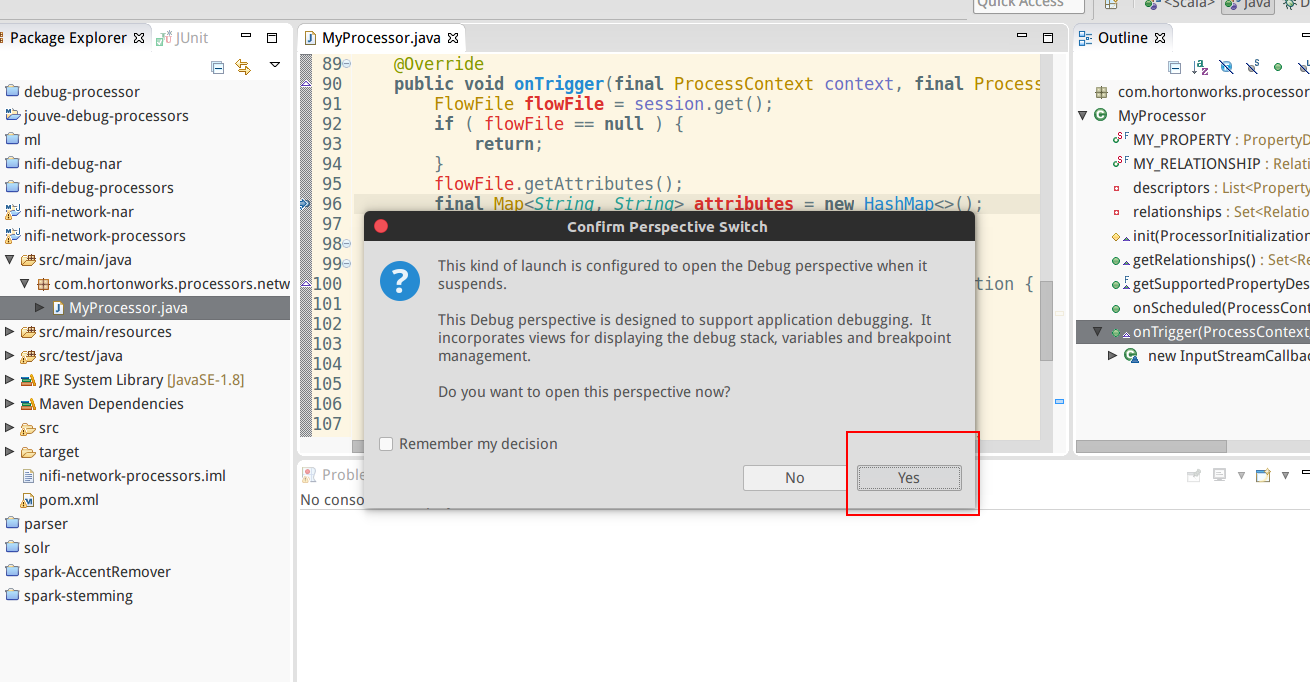
Start the Apache Nifi process and your IDE will stop at the breakpoint.
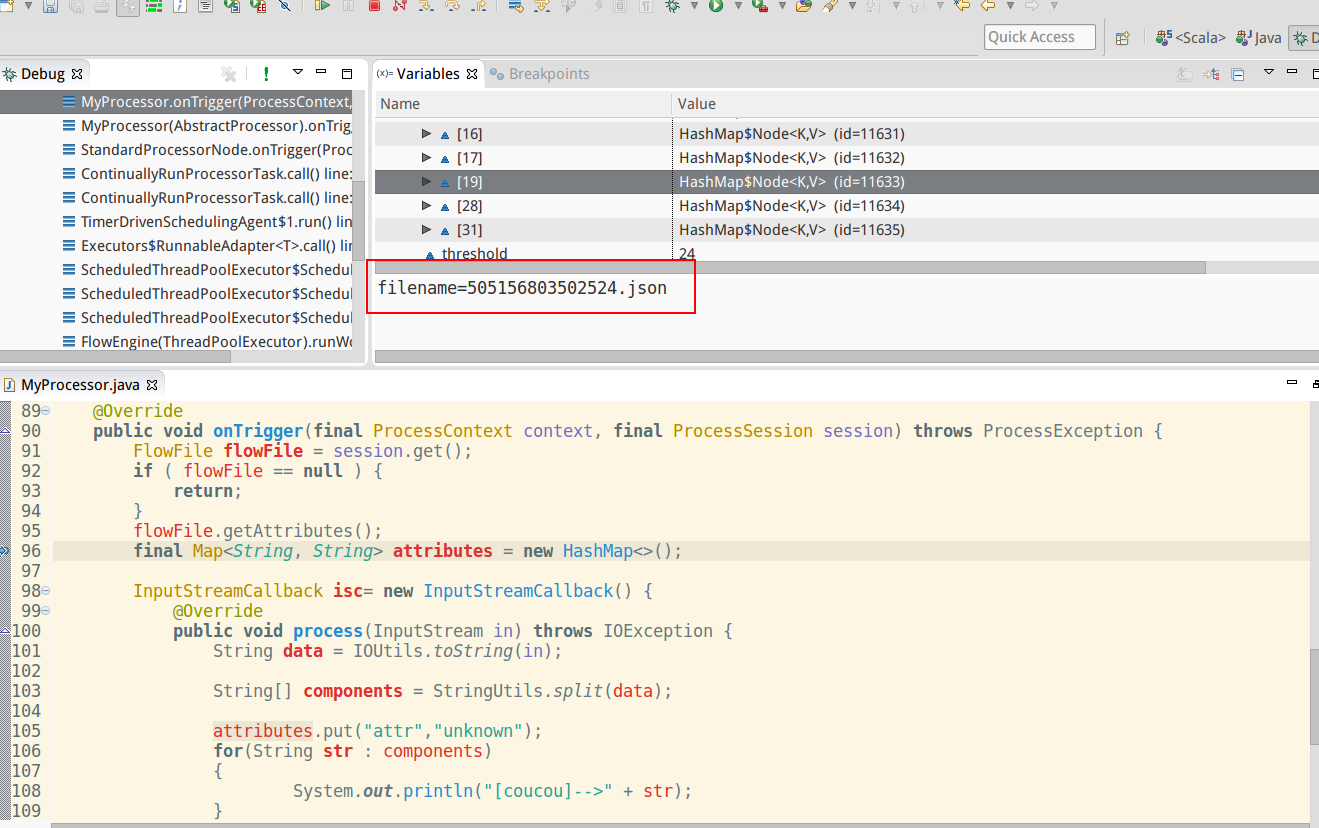
So you can use your IDE for debug :)
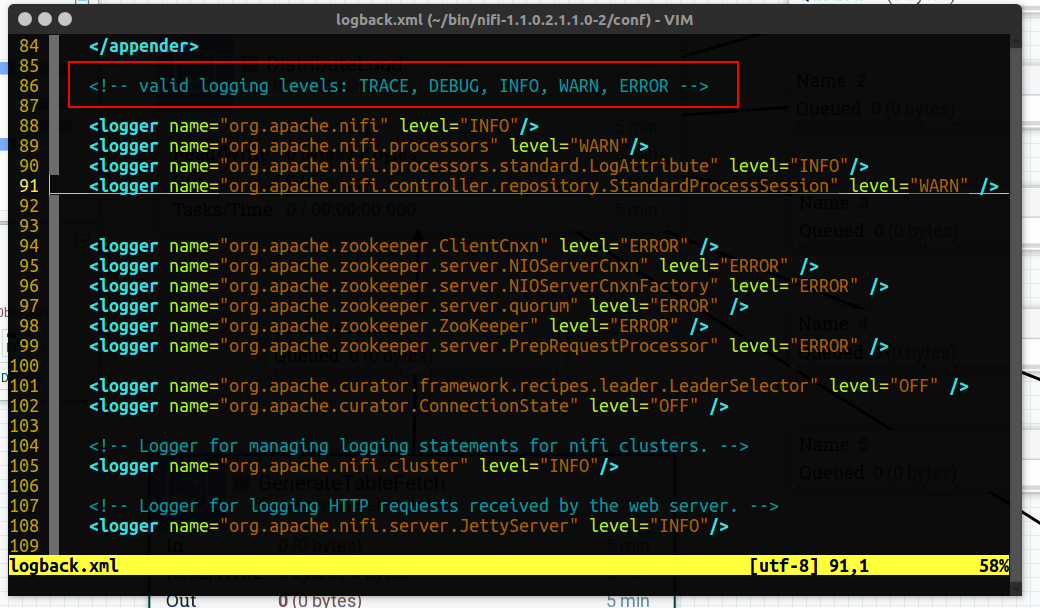
2.5.3 Bulletin(log) Level
Bulletin level could be changed by modifying configure processor, there is 4 level in Web UI
WARN,DEBUG,INFO,ERROR, by default is WARN.
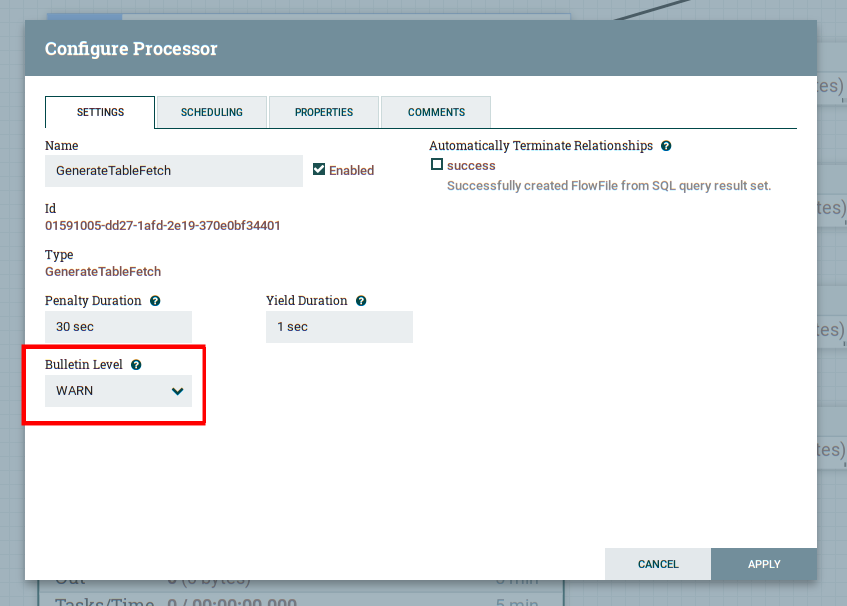
You can change the default log level by change conf/logback.xml, then you can change log level by TRACE, so all the log could be saved in logs/nifi-apps.log.
2.6 Index the data in ElasticSearch by using PostgreSQL
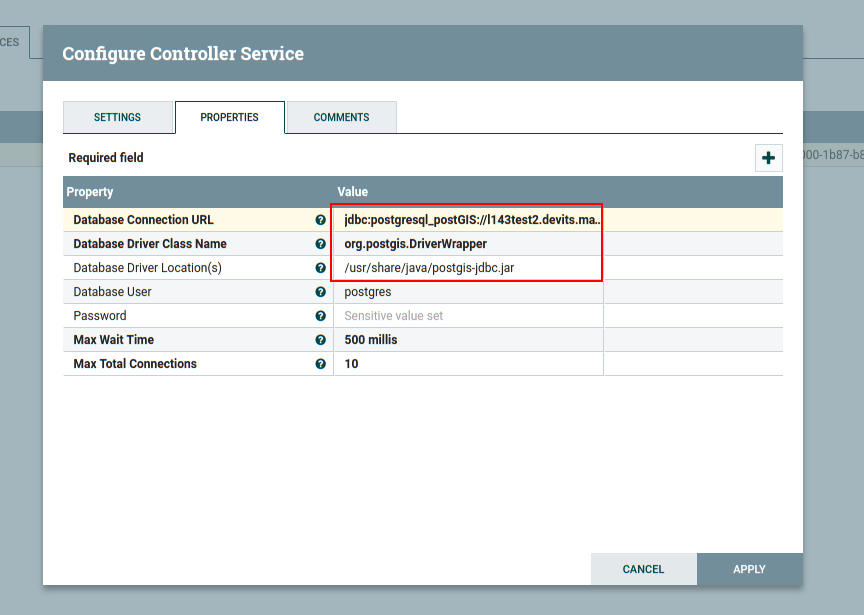
2.6.1 JDBC driver
Un exception could be showed, if you use geometry type in PostgreSQL
Exception: java.lang.IllegalArgumentException: createSchema: Unknown SQL type 1111 cannot be converted to Avro type.
We can't use the geometry type, geometry type is an addition plugin in libpostgis-java library, you must preparer your postgis-jdbc.jar
# add ppa to your system
sudo add-apt-repository ppa:ubuntugis/ppa
sudo apt-get update
# install
sudo apt-get install libpostgis-java
# to find the shema postgis-jdbc
dpkg -L libpostgis-java
/usr/share/java/postgis-jdbc.jar
Then you must put postgis-jdbc.jar and posgrelsql-driver.jar in "lib" and restart nifi.
- These files could be found in lib.
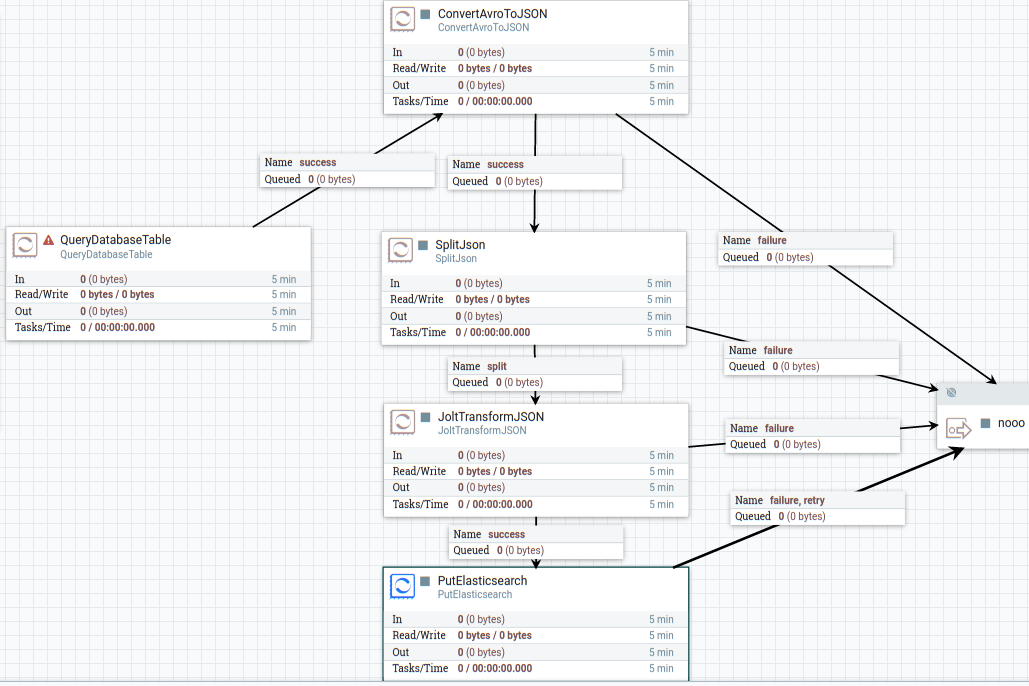
2.6.2 QueryDatabaseTable (1)
First create QueryDatabaseTable processus, click the flash and add DBCPCOnnectionPool
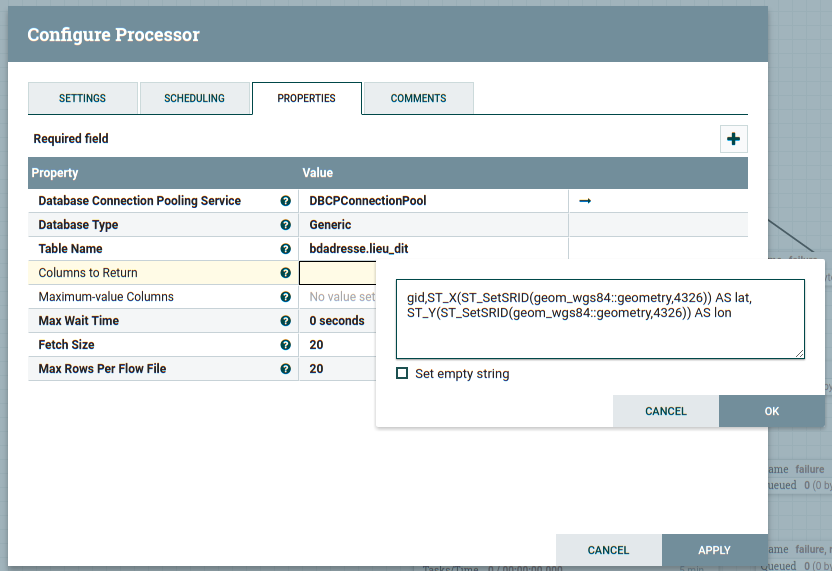
In DBCPCOnnectionPool, you put these information.
jdbc:postgresql_postGIS://l143test2.devits.mayenne.l121:5432/brgm
To consulte geometry type by using sql.
select
ST_X(ST_SetSRID(geom_wgs84::geometry,4326)) AS "location.lat",
ST_Y(ST_SetSRID(geom_wgs84::geometry,4326)) AS "location.lon"
from bdadresse.lieu_dit limit 10
Select
concat_ws(',',ST_Y(ST_SetSRID(geom_wgs84::geometry,4326)),ST_X(ST_SetSRID(geom_wgs84::geometry,4326))) AS coordinates
From bdadresse.lieu_dit
limit 100
ST_SetSRID: Set the SRID on a geometry to a particular integer value.
Reference ST_SetSRID, EPSG:4326
We could re-format the Input JSON by using JoltTransformJSON.
===> input
{
"gid" : 393857,
"lat" : -0.3831046220646078,
"lon" : 43.71104834901107
}
===> joltTransform
[
{
"operation": "shift",
"spec": {
"*": "&",
"lon": "coordinates",
"lat": "coordinates"
}
}
]
===> output
{
"gid": 326966,
"coordinates": [
-1.9834433520343622,
47.88458910168975
]
}
The work flow likes that, you could find the template file in source.
The mapping file in ElasticSearch
DELETE /adresse
PUT /adresse
PUT /adresse/
{
"mappings": {
"default": {
"properties": {
"coordinates": {
"type": "geo_point"
},
"gid": {
"type": "long"
}
}
}
}
}
// the disk usage.
GET _cat/indices
2.6.3 QueryDatabaseTable (2)
This article explains how to configure the QueryDatabaseTable processor such that it will only return "new" or "added" rows from a database.
In QueryDatabaseTable you can use the function witch in database.
gid,concat_ws(',',ST_Y(ST_SetSRID(geom_wgs84::geometry,4326)),ST_X(ST_SetSRID(geom_wgs84::geometry,4326))) AS coordinates,id,origin_nom,nom,importance,nature,extraction,recette
With this processor you will wait until the query finish, if there was a lot of data, maybe you will wait for 5 minutes. The data will charge in memory, i got an "OutOfMemory" exception.
-
-
NIFI-2866: The Initial Max Value of QueryDatabaseTable won't be case sensitive. will be fixed in version 1.2
-
Then you need cut your query in some small queries in order to balance the query time and problem of memory, you could use GenerateTableFetch.
2.6.4 GenerateTableFetch (beta)
Generates SQL select queries that fetch "pages" of rows from a table.
The partition size property, along with the table's row count, determine the size and number of pages and generated FlowFiles.
The query was generated like that, but OFFSET is bad for skipping previous rows. In our case, some queries with "offset > 1000000" take a lot of time.
select xxx
from table
order by id
limit xxx
offset xxx
If it exists an index in sql database, we want to benefit the performance, you could use the where condition, but GenerateTableFetch can't do that.
select xxx
from table
where id > last_id
order by id
limit xxx
The solution is that use the where condition with id indexed. So i tried to add a new field in this processor.
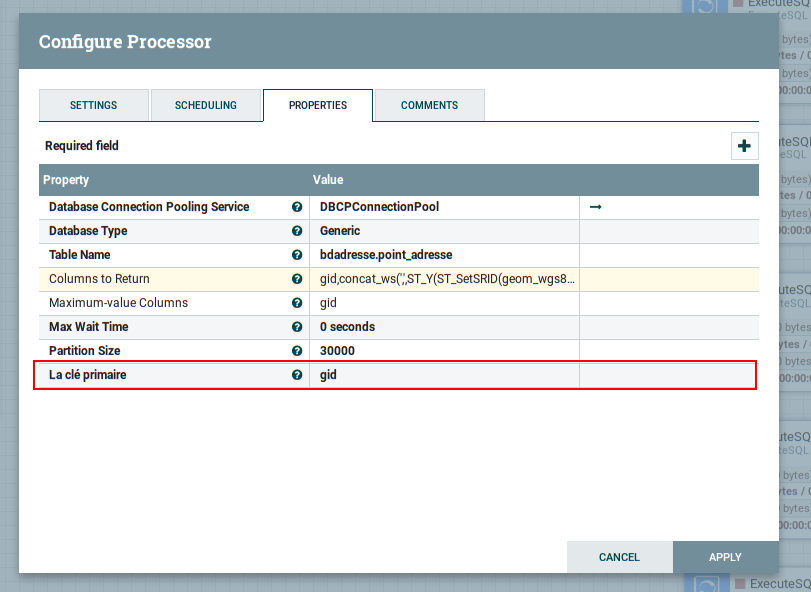
So the queries can be generated in a right way. If your use null in this column, it means that using the default processor (with offset).
To compile these code, clone nifi porject from git.
Execute mvn clean install or for parallel build execute mvn -T 2.0C clean install
git clone https://github.com/apache/nifi.git
#cd nifi
cd nifi/nifi-nar-bundles/nifi-standard-bundle/nifi-standard-processors/
# to get nar
mvn clear package
# the nar file will be created in nifi-standard-nar
The nifi-standard-nar-1.2.0-SNAPSHOT.nar must put in lib and restart nifi.
I created a jira ticket in issues.apache.org NIFI-3268
and a PR NIFI-3268 Add AUTO_INCREMENT column in GenerateTableFetch to benefit index
I hope that this processor will be improved officially.
2.6.5 DistributedLoad
Distributes FlowFiles to downstream processors based on a Distribution Strategy.
If using the Round Robin strategy, the default is to assign each destination a weighting of 1 (evenly distributed).
The flow-files can distribute sur the remote machine or processors.
2.6.6 ReplaceText
Updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.
Examples:
//input json
{"gid": 30, "coordinates": "45.8431790218448612,5.42932415510516275", "id": "PAIHABIT0000000008738125", "nom": "la champagne", "nature": "Lieu-dit habité"}
{"gid": 31, "coordinates": "45.8415304654800124,5.43492449207476813", "id": "PAIHABIT0000000008738124", "nom": "la croix trieux", "nature": "Lieu-dit habité"}
{"gid": 32, "coordinates": "45.8629110283579848,4.95922451817658683", "id": "PAIHABIT0000000008738079", "nom": "les balmes", "nature": "Lieu-dit habité"}
...
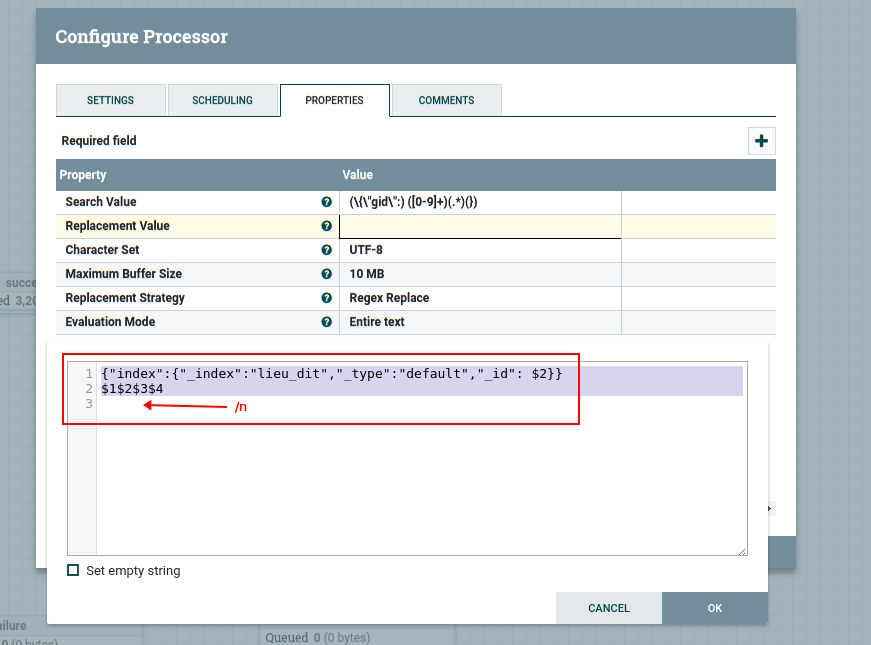
To use ElasticSearch bulk API, we must add a header for eache data and \n for each data.
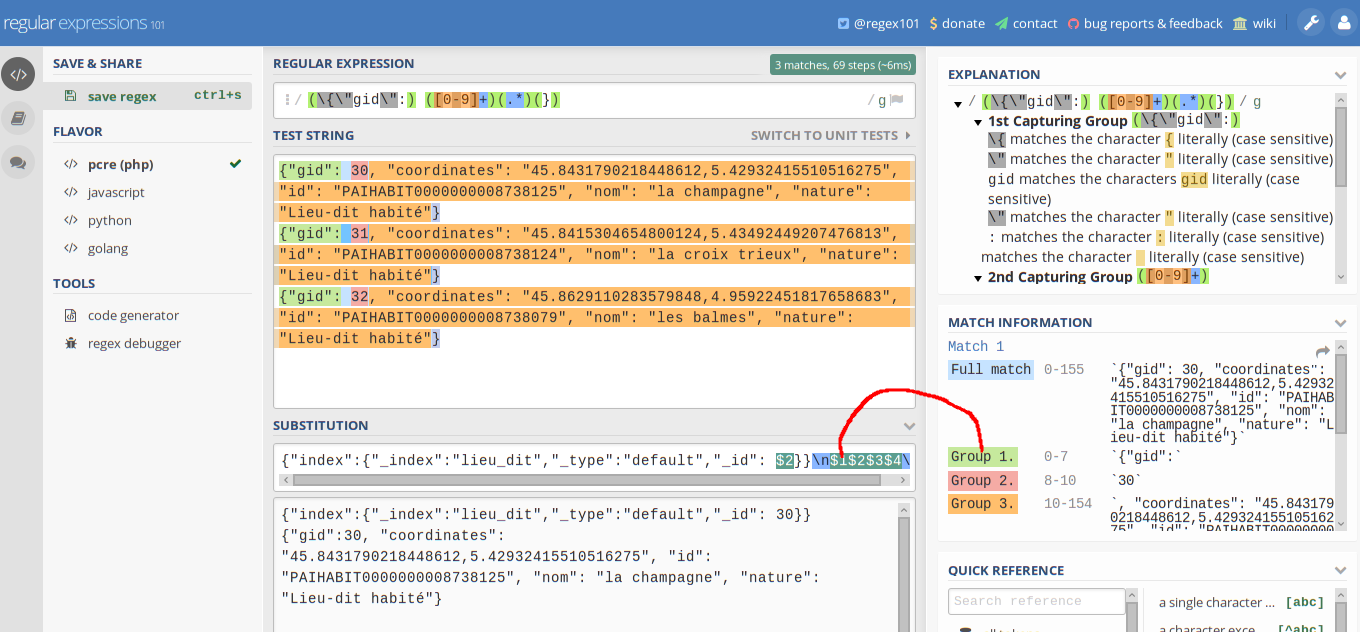
// output
{"index":{"_index":"lieu_dit","_type":"default","_id": 30}}
{"gid":30, "coordinates": "45.8431790218448612,5.42932415510516275", "id": "PAIHABIT0000000008738125", "nom": "la champagne", "nature": "Lieu-dit habité"}
{"index":{"_index":"lieu_dit","_type":"default","_id": 31}}
{"gid":31, "coordinates": "45.8415304654800124,5.43492449207476813", "id": "PAIHABIT0000000008738124", "nom": "la croix trieux", "nature": "Lieu-dit habité"}
{"index":{"_index":"lieu_dit","_type":"default","_id": 32}}
{"gid":32, "coordinates": "45.8629110283579848,4.95922451817658683", "id": "PAIHABIT0000000008738079", "nom": "les balmes", "nature": "Lieu-dit habité"}
2.6.7 putElasticsearchHttp
Writes the contents of a FlowFile to Elasticsearch, using the specified parameters such as the index to insert into and the type of the document.
But it can't index the json array, this processor uses bulk api ... We could improve it or wait for an update. So i tried to user PostHttp
REF splitJSON processor
DocumentContext documentContext;
documentContext = validateAndEstablishJsonContext(processSession, original);
final JsonPath jsonPath = JSON_PATH_REF.get();
Object jsonPathResult = documentContext.read(jsonPath);
if (!(jsonPathResult instanceof List)) {
processSession.transfer(original, REL_FAILURE);
}
List resultList = (List) jsonPathResult;
2.6.8 PostHttp
- url : http://localhost:9200/lieu_dit/_bulk
- Send as FlowFile : false
- Use Chunked Encoding : false
2.6.9 When Apache nifi desn't work
When NiFi first starts up, the following files and directories are created:
- content_repository
- database_repository
- flowfile_repository
- provenance_repository
- work directory
- logs directory
- Within the conf directory, the flow.xml.gz file and the templates directory are created.
These folds created by lancement of Apache NIFI.
The flow-file template was saved in flow.xml.gz
rm -Rf content_repository flowfile_repository database_repository provenance_repository
The flow-files were stocked in these repositories, if you have problems for starting or you can't restart Apache nifi, you could remove them.
3. PostgreSQL
PostgreSQL has its own access control, so you must add your IP adress in the config file.
sudo vi /projet/pgsql/9.5/data/pg_hba.conf
# IP adress
host all all 127.0.0.1/32 md5
host all all 192.168.0.0/16 md5
host all all 10.53.0.0/16 md5
4. ElasticSearch Cluster
To set up ElasticSearch Cluster is simple. Just change elasticsearch.yml.
# ======================== Elasticsearch Configuration =========================
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: hdfexpertise
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: engine-serv15
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /data/es/elasticsearch-2.4.1/data
#
# Path to log files:
#
path.logs: /data/es/elasticsearch-2.4.1/logs
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["engine-serv15", "engine-serv11","engine-serv10","engine-serv04","engine-serv03"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1):
#
discovery.zen.minimum_master_nodes: 3
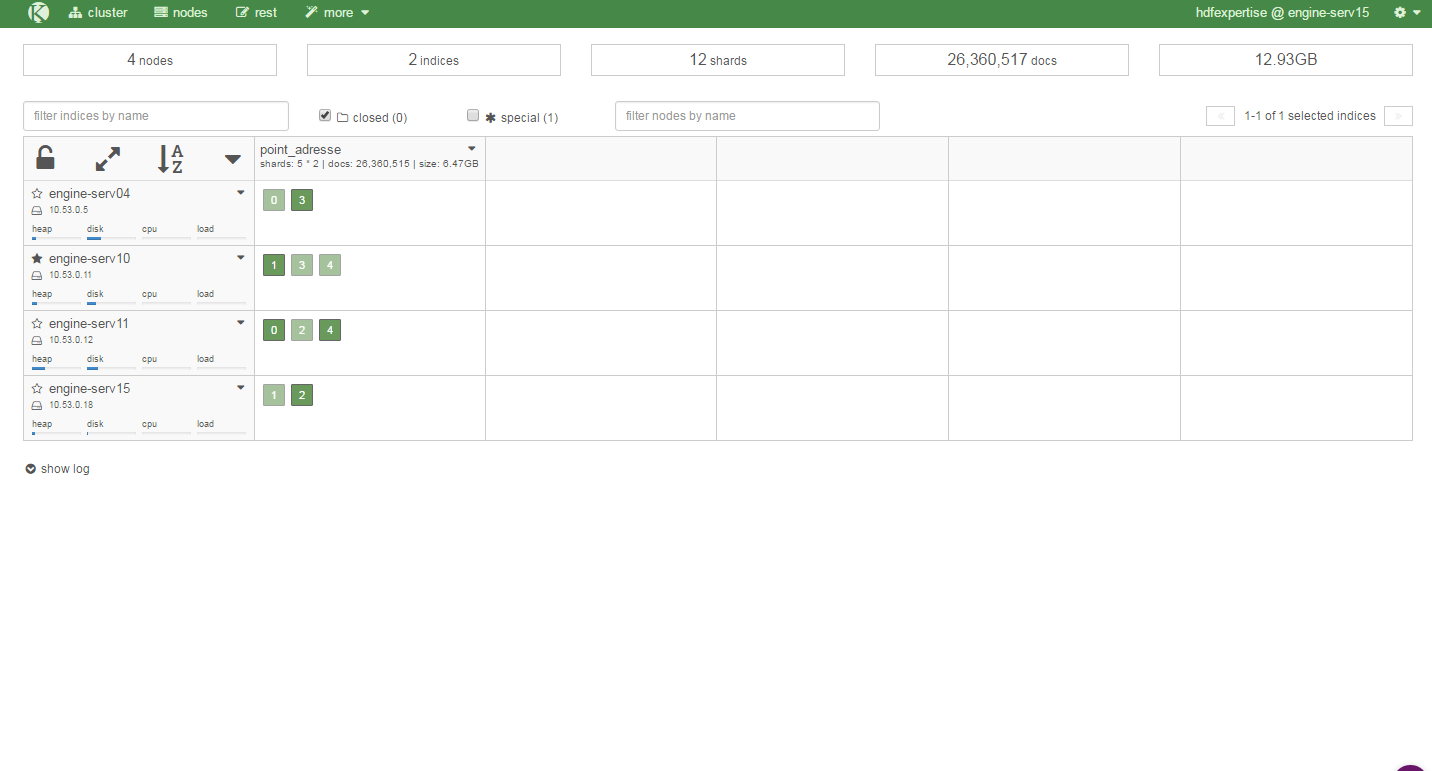
5. Final
- Apache nifi : 1 vm
- Elasticsearch : 4 vm
- Total : 5 vm
Mapping for elasticsearch
PUT point_adresse/
{
"mappings": {
"default": {
"properties": {
"coordinates": {
"type": "geo_point"
},
"gid": {
"type": "long"
}
}
}
}
}
This workflow could be found in source/Template_for_point_adresse.xml
- PostgreSQL -> Data -> JSON -> Elasticsearch
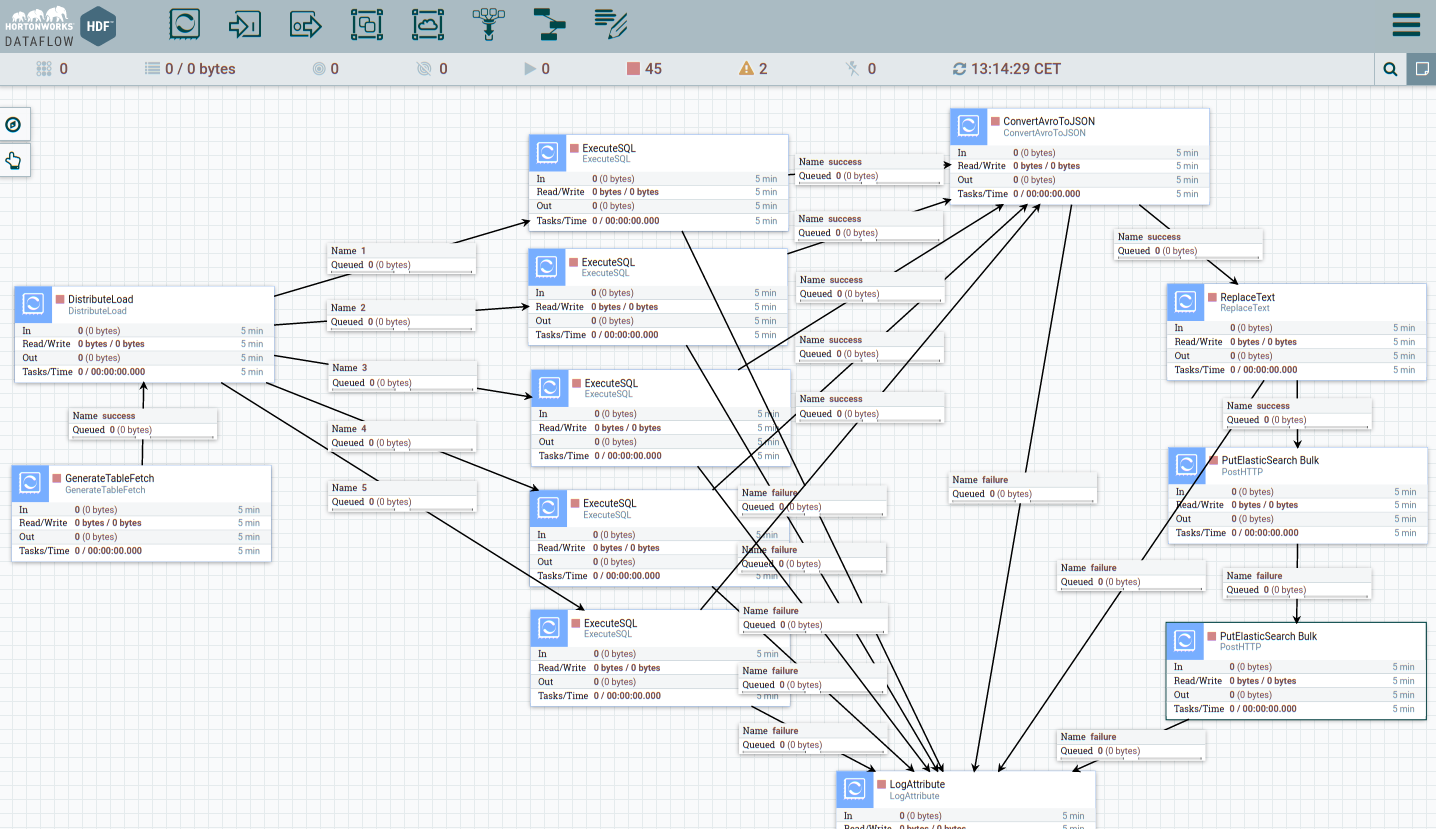
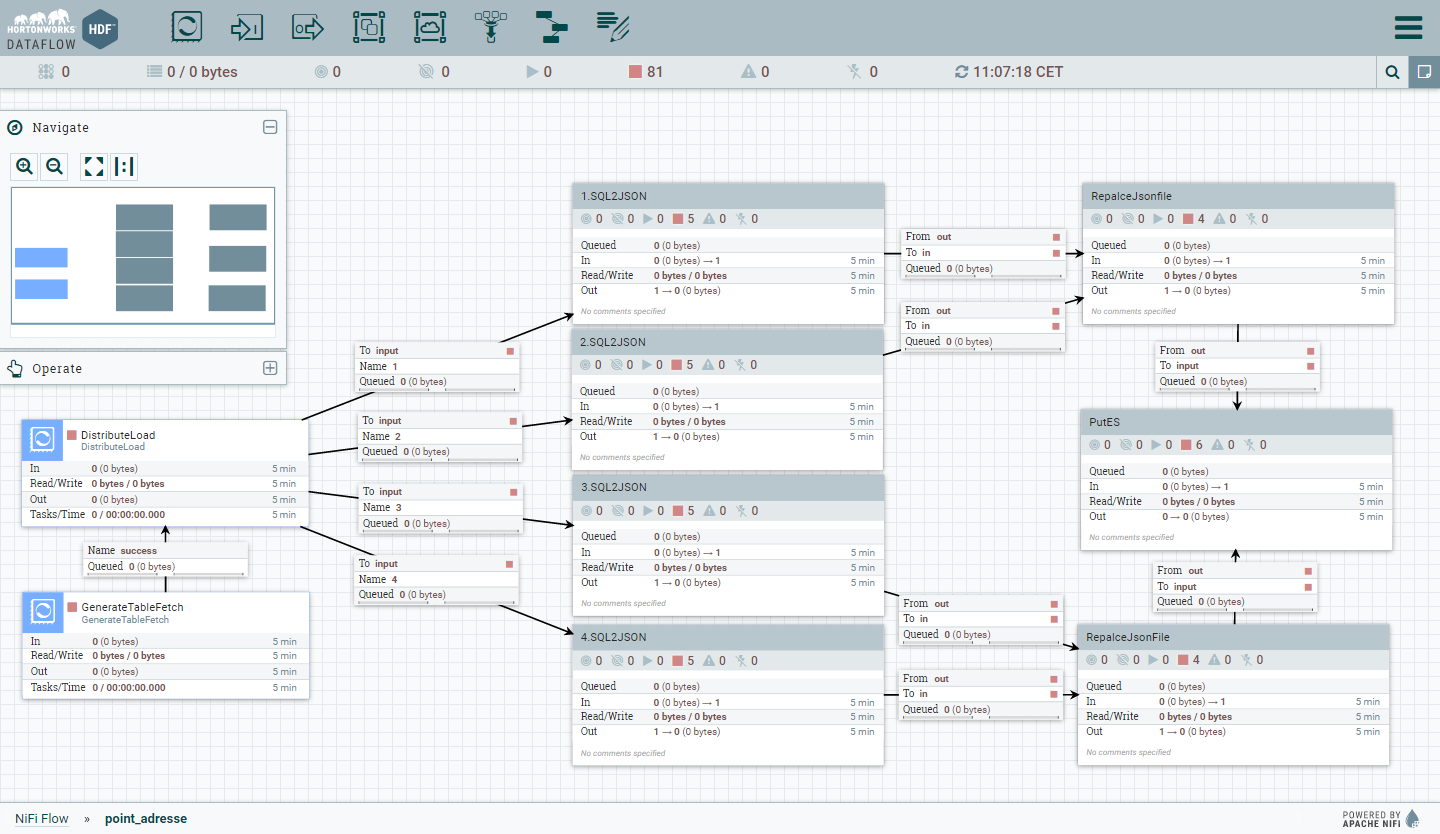
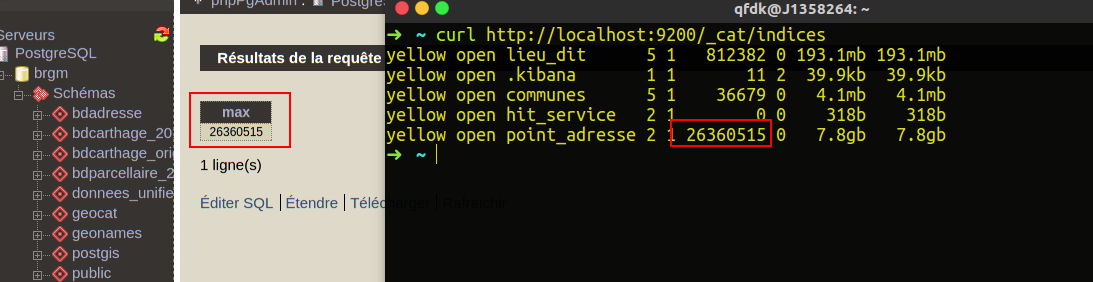
Total time : 16 minutes
Todolist
- Apache nifi with els VS Apache Camel with Solr
References
- [1]“Apache NiFi Expression Language Guide,” 27-Dec-2016. [Online]. Available: https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html. [Accessed: 27-Dec-2016].
- [2]“Apche NIFI : problem by using QueryDatabaseTable and putelasticsearch - Hortonworks.” [Online]. Available: https://community.hortonworks.com/questions/72586/how-can-i-use-an-array-with-putelasticsearch.html#answer-75159. [Accessed: 29-Dec-2016].
- [3]“Creating a Process Group for Twitter Data in NiFi - Hortonworks.” [Online]. Available: https://community.hortonworks.com/articles/58915/creating-a-process-group-for-twitter-data-in-nifi.html. [Accessed: 29-Dec-2016].
- [4]“Enabling the Zeppelin Elasticsearch interpreter - Hortonworks.” [Online]. Available: https://community.hortonworks.com/articles/54755/enabling-the-zeppelin-elasticsearch-interpreter.html. [Accessed: 29-Dec-2016].
- [5]“Incremental Fetch in NiFi with QueryDatabaseTable - Hortonworks,” 27-Dec-2016. [Online]. Available: https://community.hortonworks.com/articles/51902/incremental-fetch-in-nifi-with-querydatabasetable.html. [Accessed: 27-Dec-2016].
- [6]“Jolt Transform Demo,” 27-Dec-2016. [Online]. Available: http://jolt-demo.appspot.com/#inception. [Accessed: 27-Dec-2016].
- [7]“lmenezes/elasticsearch-kopf,” GitHub, 27-Dec-2016. [Online]. Available: https://github.com/lmenezes/elasticsearch-kopf. [Accessed: 27-Dec-2016].
- [8]“OFFSET is bad for skipping previous rows.” [Online]. Available: http://Use-The-Index-Luke.com/sql/partial-results/fetch-next-page. [Accessed: 27-Dec-2016].
- [9]“Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript.” [Online]. Available: https://regex101.com/. [Accessed: 27-Dec-2016].
- [10]“ST_SetSRID,” 27-Dec-2016. [Online]. Available: http://postgis.net/docs/ST_SetSRID.html. [Accessed: 27-Dec-2016].
- [11]“Using NiFi GetTwitter, UpdateAttributes and ReplaceText processors to modify Twitter JSON data. - Hortonworks.” [Online]. Available: https://community.hortonworks.com/articles/57803/using-nifi-gettwitter-updateattributes-and-replace.html. [Accessed: 29-Dec-2016].
- [12]“WGS 84: EPSG Projection -- Spatial Reference,” 27-Dec-2016. [Online]. Available: http://spatialreference.org/ref/epsg/wgs-84/. [Accessed: 27-Dec-2016].
This blog is pretty good!And I got many knowleges about nifi,thank you very much.Oh,my friend ...
This blog is pretty good! It is very useful for me.